QSearch - (Universidade Nova de Lisboa, 2012-2014)
Role: Investigator.
National AdI funding.
O projecto QSEARCH propõe-se desenvolver tecnologia que permita o melhor acesso e gestão de documentos. Para tal,
este projecto tem como objectivo o desenvolvimento tecnológico de: (1)
técnicas de análise de documentos textuais para extracção de
informação, (2) técnicas avançadas de pesquisa, e (3) interfaces de
utilizador orientadas à navegação multifacetada. Estas tecnologias
representam actualmente as funcionalidades que os utilizadores de
sistemas de gestão documental necessitam para aumentar a sua
produtividade. Estas necessidades enquadram-se na estratégia de
optimização do acesso aos arquivos de informação.
CS4E - Compressed sensing for media search engines (Universidade Nova de Lisboa, 2011-2014)
Role: Principal Investigator.
National FCT funding.
A number of information exploration applications have recently
emerged providing access to rich media, e.g., Flickr, YouTube and
Wikipedia. These applications are used for both entertainment and
professional purposes. The success of these applications is closely
related to the users’ role in the information-processing chain: users
generate content, metadata and provide valuable feedback concerning
information relevance. Systems collect vast amounts of user interaction
data such as queries, click data, annotations, comments and new
content. These diverse sources of information create two critical
challenges to traditional indexing and search techniques: (1) mining
the relevant information from a large number of sources and (2)
matching the user query to the extracted information.
The main hypothesis of this project is that compressed sensing techniques will define the new state-of-the-art for multimedia information retrieval. This hypothesis is supported by two facts. The first fact is related to the L1 minimization criterion: rich media applications need to handle information with a large number of variables, and sparse models, as the ones computed by compressed sensing techniques, can indeed reduce the number of information sources. The second fact is related to the large-scale resources available that allow the inference of a sparse representation of media documents.
ImTV - Immersive TV for communities of media consumers and producers (Universidade Nova de Lisboa, 2010-2013)
Role: Principal Investigator.
National FCT funding.
Millions of users now look for video entertainment not only on their favorite TV channels or cinemas, but also online – an example of this paradigm shift is the YouTube live transmission of a U2 band concert. High-quality entertainment video shows are now created by professionals, independent producers and amateurs that publish their media online and free of charge. While this new media workflow creates added-value services for end-users (e.g., personalizing their TV viewing), it also breaks traditional TV concepts and affects key economic functions such as program scheduling, audience measurement, and targeted advertisement.
The long-term vision of this proposal is to exploit the full potential of new trends in media production and consumption by devising an on-demand immersive-TV framework combining TV industry, Internet distribution models and end-user’s needs/interests.
ARIA - Ambient-assisted reading interfaces (Universidade Nova de Lisboa, 2010-2012)
Role: Researcher.
National FCT funding.
Forgetting what one has just read is, in some cases, linked to insufficient attention. The reader might feel either bored or distracted by something more interesting – a common trace in children and the elderly. The challenge is: how can multimedia systems assist readers in reading and remembering stories? Several studies showed that reading memory is improved by visual stimulus.
In this project we formulate the hypothesis that an automated multimedia system can help users in reading a story by stimulating their reading memory with adequate visual illustrations. These illustrations are intended to increase the readers’ attention towards the story and to help them recalling the story. Moreover, we aim at analysing the user facial expressions as a reaction to the presented information and apply feedback mechnamisms to adapt the system to the user interests.
X-Media: Large scale cross-media IE (University of Sheffield, 2007-2008)
Role: Researcher.
EU FP7 funding.
X-Media addresses the issue of knowledge management in complex distributed environments. It will study, develop and implement large scale methodologies and techniques for knowledge management able to support sharing and reuse of knowledge that is distributed in different media (images, documents and data) and repositories (data bases, knowledge bases, document repositories, etc.).
This is a large EU funded project, please visit its web page.
Semantic Multimedia IR (Imperial College London, 2004-2008)
The extraction of semantic information from multimedia content is a research topic that tries to mimic the way human perception works, and therefore is highly related to artificial intelligence. However, human perception is still too far from being completely understood at a level that we can imitate its functions in a computational system. Nowadays, applications that make use of the semantics of multimedia content depend on manual annotations and other information extracted from the surrounding content (e.g. alternate text). This way of extracting multimedia’ semantics is flawed and costly. Doing the entire process automatically (or even semi-automatically), can greatly decrease the operational and maintenance costs of such applications.
The aim of this research is to enhance multimedia retrieval applications by combining both knowledge and statistical data in a learning framework to extract semantic information from multimedia. We will approach the problem as a Bayesian learning problem divided in three parts:
- Multimedia mining: mines the feature space for the problem’s most common patterns and learns the causality relations between the occurrence of these patterns and keywords;
- Multi-modal information fusion: multi-modal features will be combined in a statistical framework to increase the prediction accuracy of keywords in new unseen content.
- Semantic information extraction: improve the inference results obtained in the previous steps by using knowledge about keywords co-occurrences.
Universal Multimedia Access (Instituto Superior Técnico/Siemens R&D, 2000-2002)
The access to multimedia information by any terminal through any network is a new concept referred as Universal Multimedia Access (UMA). The objective of UMA technology is to make available different presentations of the same information, more or less complex, e.g., in terms of media types, suiting different terminals, networks and user preferences. This can be achieved through customizing the content to the environment where it shall be consumed.
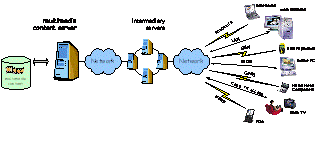
The content customization can be implemented in three different places: 1) at the content server, 2) at a proxy server, and 3) at the user terminal. The developed system, implements the customization engine at the content server and at a proxy server.